1、正则表达式匹配的步骤
导入正则表达式模块import re
使用re.complice()方法创建正则表达式对象
把你想搜索的文本传递给上一步的正则表达式对象的search()方法
用上一步返回的对象调用group()方法,返回匹配的文本
美国的电话号码格式是3数字-3数字-4数字,例如,999-999-9999,我们用正则的方法来从一段文本中查找满足这个格式的电话号码并输出:
# '\d{3}-\d{3}-\d{4}'指要匹配的格式,\d表示数字,{3}表示重复前的格式3次,\d{3}指重复前的数字3次
honeNumRegex = re.compile(r'\d{3}-\d{3}-\d{4}')
mo = phoneNumRegex.search('My number is 415-555-4242.')
print('Phone number found: ' + mo.group())
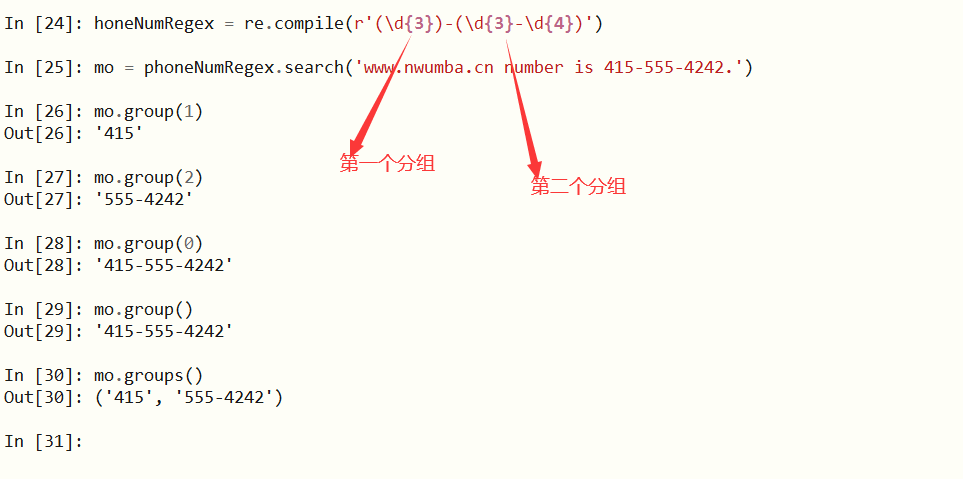
2、对获取的文本进行分组
你可以对要搜索的格式中的部分字符串用括号括起来,括起来的部分叫做一组,可以调用后期search()方法返回对象的group(arg)方法来单独获取括起来部分的匹配文本,arg为1时对应格式中的第一个括号,依次类推,如果arg的参数为0或者为空,表示获取整个匹配的文本。
当然,也可以调用groups()方法一次来获取所有的分组。
如果你的格式字符串里面本身含有特殊字符(这些字符在模式匹配中有意义),需要用\进行转义,目前在格式字符中需要转义的字符如下所示:
\. \^ \$ \* \+ \? \{ \} \[ \] \\ \| \( \)
3、|(或者操作符)
|表示或,两边的字符串谁先出现就先被匹配
4、?(问号)
?表示匹配前面括起来的模式0次或者1次
5、*(星号)
*表示重复前的组0次或者多次

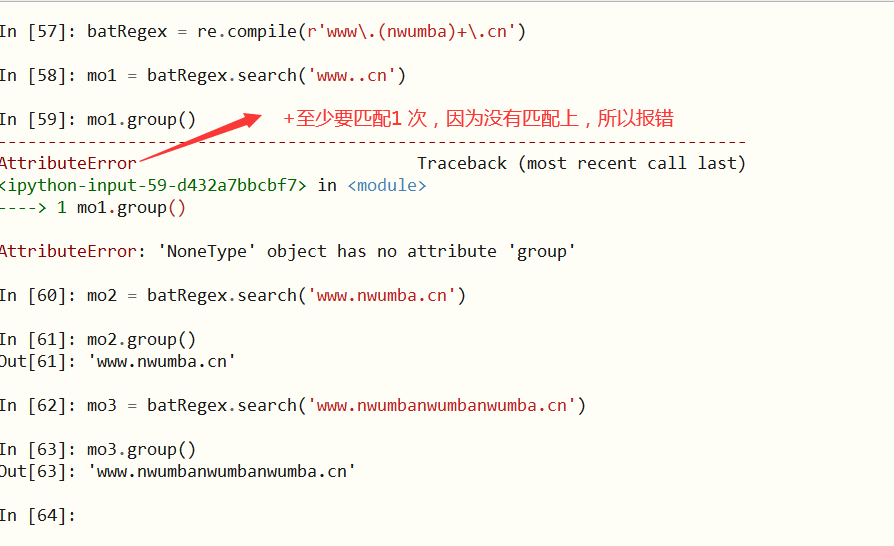
6、+(加号)
匹配前面的分组一次或者多次
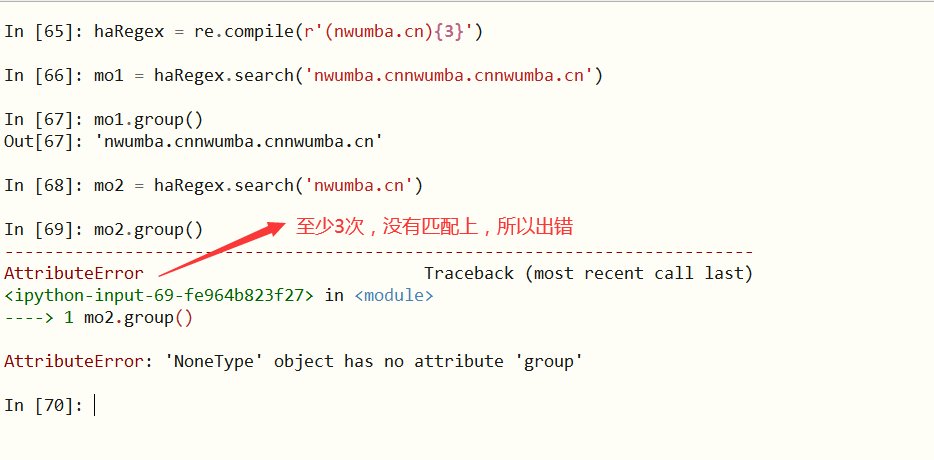
7、{}(中括号)
{min,max}表示匹配前的分组至少min次,至多max次
省略min,指匹配前面的分组0次至max次
省略max,批匹配前面的分组至少min次
8、贪婪匹配和非贪婪匹配
贪婪匹配:这是python正则表达式的默认模式,匹配最长的字符(模式)
非贪匹配:{}?,中括号后面加问号,匹配最短的字符(模式)

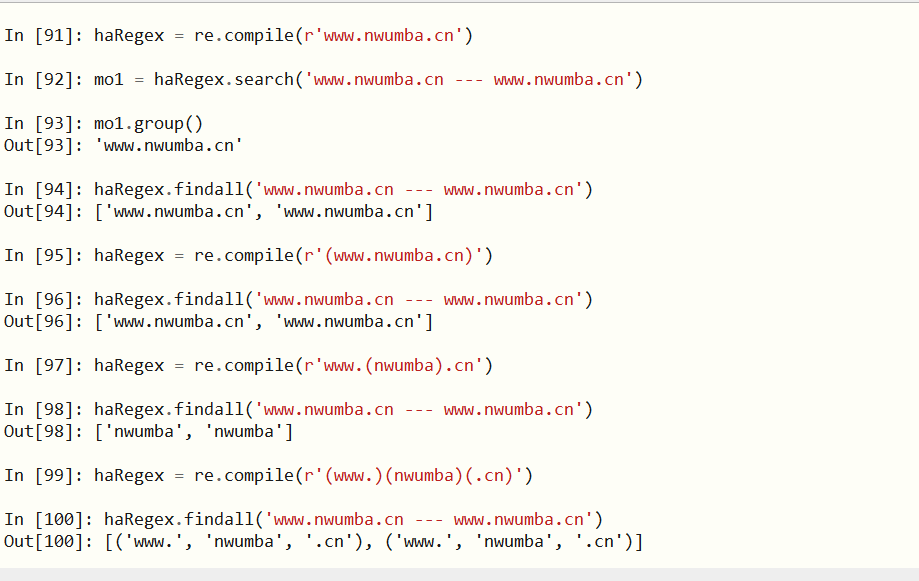
9、findall()
search()方法只会返回第一个匹配的文本,而findall()会返回一个列表,这个列表会包括所有匹配的文本,如果模式分组了,那么会返回一个包括元组的列表。
10、常见的模式匹配速记符
|
速记符 |
说明 |
|
\d |
代表0-9这10个数字 |
|
\D |
除了数字外的其他字符 |
|
\w |
代表字母、数字、下划线 |
|
\W |
除了字母、数字、下划线的其他字符 |
|
\s |
代表空格、tab、换行符 |
|
\S |
除了空格、tab、换行符的其他字符 |
|
[] |
代表范围内的某个字符,[a-zA-Z]代表一个字母,大写小写都可以,[]里的字符不用做转义,比如.不用写成\.,也可以在[]里加^,表示除了中括号里的其他字符 |
|
^ |
以某个字符串打头 |
|
$ |
以某个字符串结尾 |
|
. |
匹配除换行符以外的任意一个字符 |
|
.* |
任意长的任意字符,默认是贪婪匹配,.*?是非贪婪匹配 |
|
|
|
|
|
|
11、忽略大小写匹配
默认情况下,模式以指定的大小写匹配文本,但你可以传递re.IGNORECASE或者re.I来忽略大小写

12、sub()
sub(str,re_str): 这个函数用str这个字符串替换re_str匹配到的文本。str中还可以使用\1这种引用匹配文件中的分组,默认只显示匹配到分组的第一个字符。

13、复杂正则表达式跨多行书写
如果正则表达式比较复杂,那如果写在一行会很难阅读,可以使用re.complice()的第二个参数re.VERBOSE,这个参数表明这个正则表达式可以跨多行书写,python会忽略空格和注释
例如:
phoneRegex = re.compile(r'''(
(\d{3}|\(\d{3}\))? # area code
(\s|-|\.)? # separator
\d{3} # first 3 digits
(\s|-|\.) # separator
\d{4} # last 4 digits
(\s*(ext|x|ext.)\s*\d{2,5})? # extension
)''', re.VERBOSE)
14、re.IGNORECASE、re.DOTALL(.代表所有字符,包括换行符)、re.VERBOSE
可以用|结合这几个参数,例如re.IGNORECASE | re.DOTALL | re.VERBOSE
15、综合实例
从剪贴板中获取文本,并用正则去匹配美国电话号码和email,类似的程序很多,比如找url地址、找日期、去除敏感信息、去除多个空格或者重复的词语,可以把此程序稍作改动即可
#! python3
# phoneAndEmail.py -从剪贴板中找美国电话号码和email地址
import pyperclip, re
# 匹配电话号码的正则
phoneRegex = re.compile(r'''(
(\d{3}|\(\d{3}\))? # 区号为3个数字
(\s|-|\.)? # 空格、-、.
(\d{3}) # 3个数字
(\s|-|\.) # 空格、-、.
(\d{4}) # 4个数字
(\s*(ext|x|ext.)\s*(\d{2,5}))? # ext、x、ext.加多个空格,2到5个数字
)''', re.VERBOSE)
# 匹配email的正则
emailRegex = re.compile(r'''(
[a-zA-Z0-9._%+-]+ # username
@ # @ symbol
[a-zA-Z0-9.-]+ # domain name
(\.[a-zA-Z]{2,4}) # dot-something
)''', re.VERBOSE)
# 从剪贴板中获取文本数据
text = str(pyperclip.paste())
matches = []
# 用正则匹配并把匹配的结果加入到 matches中去
for groups in phoneRegex.findall(text):
phoneNum = '-'.join([groups[1], groups[3], groups[5]])
if groups[8] != '':
phoneNum += ' x' + groups[8]
matches.append(phoneNum)
for groups in emailRegex.findall(text):
matches.append(groups[0])
# 把结果粘贴到剪贴板中去
if len(matches) > 0:
pyperclip.copy('\n'.join(matches))
print('粘贴到剪贴板中:')
print('\n'.join(matches))
else:
print('没有电话号码和email地址发现')
原创文章,转载请注明出处:http://b.nwumba.cn/article/16/